匹配(matching)是將人與人、人與物、或物與物進行一對一、多對一、或多對多的配對。電腦科學家對此議題並不陌生,圖論(graph theory)中亦有最大匹配(maximum matching)的問題,尤其是在二分圖(bipartite graph)中的最大有權重/無權重匹配,更常常用在電腦科學家的問題建模上。
不過電腦科學家或圖論學家探討的匹配問題,目標在極大化某個全域效能數值,是不會考慮被處理對象對結果的喜好的。如果是人參與的匹配,這樣的演算法會有適用性的問題,這時就該輪到賽局理論出馬了。
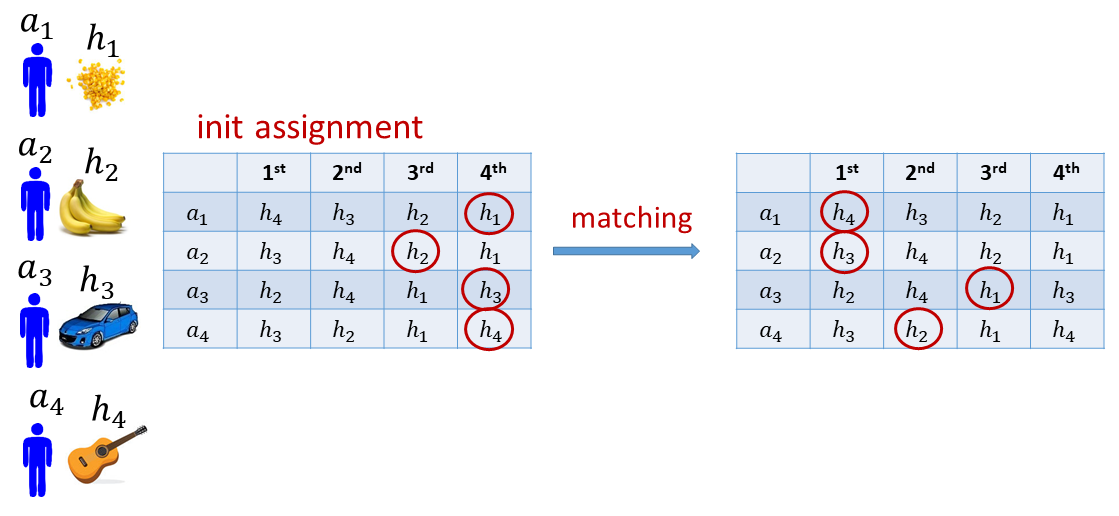
像圖中這樣四個人與四個物的配對,以及圈起來的配對結果,我們說已經達到帕雷多最適(Pareto optimal)。講白點是說此匹配已經是每個人都很滿意的結果,因為我們已經無法在沒有人會更不滿意的前提下,單獨使某人或某些人更滿意。換句話說,如果我們要使某人或某些人更滿意,勢必會有人會得到(比起現在結果)更不滿意的結果。
與優化單一目標值的傳統匹配問題不同,這種考慮到參與對象偏好(preference)的匹配問題,存在多個帕雷多最適解,因為本質上這是個多目標最佳化問題。不僅如此,將匹配視為一個合作賽局的話,匹配解還需滿足穩定性(stability)的條件。
給定一個匹配結果,如果某個或某些個參與者脫離此結果另行配對,結果不會比現在匹配的結果更差,而且至少有一個參與者對匹配結果更滿意,則此匹配結果是不穩定的。例如,圖中的匹配結果就是不穩定的。如果a3與a4脫離此賽局另外配對(交換彼此的物品),a3與a4都會更滿意。
帕雷多最適結果不見得是穩定解,穩定解(如果有的話)一定是帕雷多最適。而這只是人與物的匹配,只有單方面(人這一方面)對配對結果有偏好,另一方面是沒有的。Gale and Shapley探討的男女婚配問題,是有雙向偏好(two-sided preference)的。另外,上述提到的皆是一對一(one-to-one)匹配,更進階的問題有多對一(many-to-one)與多對多(many-to-many)配對。雙向偏好多對多匹配應該是目前最困難的問題,許多研究者還在投入研究中。
如果這樣的複雜度還無法難倒研究者,我們還可以進一步擴充偏好的表示能力。在多對一或多對多的匹配問題中,參與者對可能匹配對象的偏好是設定成對個別對象的偏好排序。實務中,參與者可能比較想對各種匹配對象的「組合」進行偏好排序。例如,如果一個學校想組一個籃球隊,在招募新生時,校方對「中鋒、前鋒、大前鋒、後衛」這樣組合的偏好程度,顯然會高過「中鋒、中鋒、中鋒、後衛」這樣的組合。如果是這樣,對於n個可能的匹配對象,我們可能需要排序O(2^n)種組合。
另外,我們上述說明隱含了偏好關係皆為全序(total ordering),如果考慮偏序(partial ordering)的偏好關係,這個問題會變得更為複雜。所以,別小看匹配這個看似簡單的問題。